
Retrieval Augmented Generation or Long Context? Which technique is better?
Predictions
There is a lot of hype around AI for how it will transform your business. And nothing has been hotter than Retrieval Augmented Generation or RAG. Here is a quick primer on what RAG is (for a more indepth definition, check out this excellent blog post from NVIDIA). RAG involves grounding an AI in external data instead of having to rely on the model having been trained on data related to your prompt. Microsoft’s Bing (now called co-pilot) is a kind of RAG system where it will take your prompt and use it to do a web search so that it can have more up to date info, better insight based on external sources, increased accuracy, and reduce hallucinations. But with the release of Google Gemini Pro 1.5 with its 1 million token context window, it begs the question, Did Google just kill RAG?
What is RAG?
A lot of people in the AI engineering space seem to think so. Why? Because setting up a good RAG system takes time. You need development resources that can dedicate the time to: install libraries, prepare data, generate embeddings, set up and connect a database, create a vector search index, establish data connection, and perform vector search on user queries. If this sounds like a lot, it is! Luckily, a lot of companies have developed tools such as pre-trained embeddings, vector databases, and search engines that are already plug and play so you don’t have to do all of this yourself.
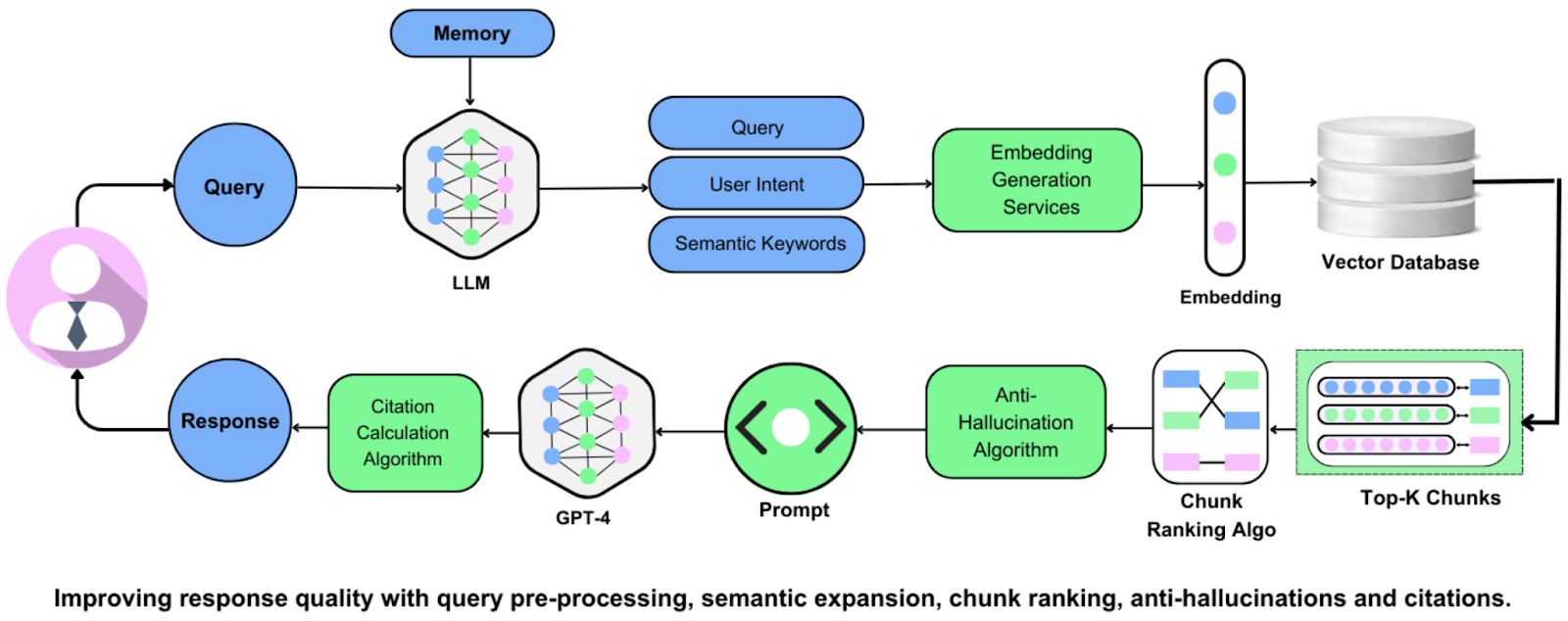
The Promise of Long Context Windows
But imagine that you didn’t have to do any of this. This is where long context comes in. The “context window” is the text field that you write in when you enter your prompt into an AI-powered chatbot like ChatGPT, or Claude. And just like how you are limited to a certain amount of characters in a Twitter post, the context window of a chatbot limits how many tokens you can enter into the chat window (1 token = .75 words). For ChatGPT, the maximum number of tokens has jumped from around 32,000 to 128,000. That is a large context window but the AI research and development company, Anthropic, cracked 200,000 tokens for their chatbot Claude’s context window.
This large context window allows for a chatbot to greatly extend the session size for a single chat session. This creates a very tailored experience where you can upload all of the info right the in the chat window without having the system go and “retrieve” the data you need. In theory this was a huge breakthrough, but in practice, it turns out that models are not very good at being able to access all of that information in the context window.
The “Lost in the Middle” Problem
Stanford University released a paper called ‘Lost in the Middle: How Language Models Use Long Contexts’. where they show that Large Language Models “are better at using relevant information that occurs at the very beginning (primacy bias) or end of its input context (recency bias), and performance degrades significantly when models must access and use information located in the middle of its input context.”
Google’s Breakthrough and Its Limitations
So why would anyone choose long-context over RAG when it’s so bad at retrieving information from the middle of the context window? This is where Google really stepped things up. In February, 2024, they announced a breakthrough with their Gemini Pro 1.5 model with it’s state-of-the-art 1 million token context window. This is five times larger than Anthropic’s Claude and almost 8 times larger than OpenAI’s GPT-4. And what about the Lost in the Middle problem? Google claims to have solved this issue with their new model, showing that Gemini has near perfect recall across the entire 1 million tokens. Heck, they have actually shown near perfect knowledge retrieval at up to 10 million tokens!

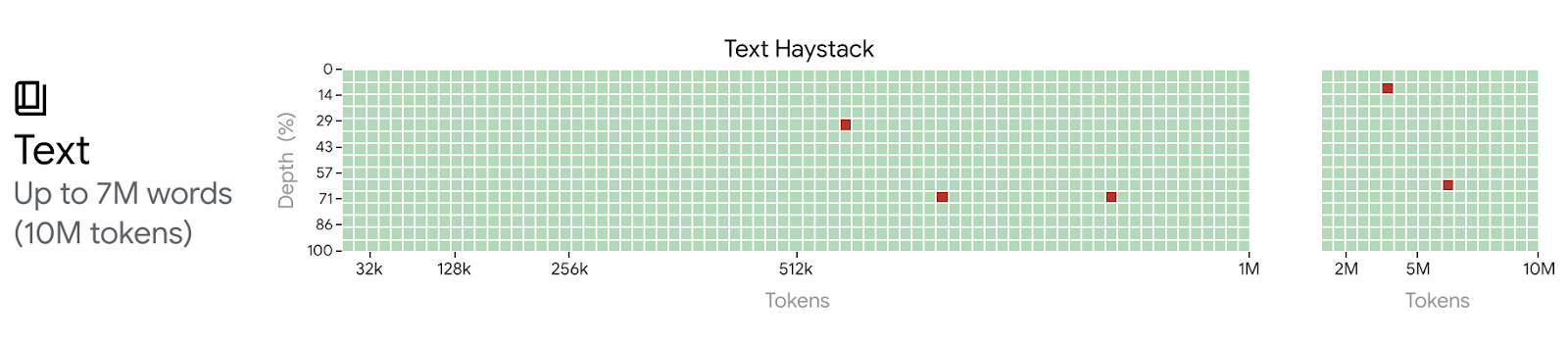
So that’s it, RAG is dead. Right?
Wrong. While long-context is an exciting new breakthrough, it’s expensive. Token’s cost money to process and the more tokens you have, the more processing costs are associated with it. And this isn’t an easily solvable problem. In fact, the problem of scale is one of the biggest challenges in AI research today.
The Case for RAG
Also, RAG systems can pull from a vast storage of different potential data sources based on the prompt. With long-context, you sort of need to know what you have to feed into the context window in order to get the real benefit. If you don’t know what info you need, then the value isn’t there regardless of the amount of tokens you can stuff into the context window.
Conclusion
In conclusion, while the advancements in long context windows are impressive, RAG remains a viable and often superior solution for many AI applications. The flexibility and cost-effectiveness of RAG systems make them a compelling choice, especially when the required information is not known in advance. As AI technology continues to evolve, we can expect further developments in both RAG and long context windows, shaping the future of AI in exciting ways.
Frequently Asked Questions
For user profiles that are 2,000 to 10,000 words, should I use long context windows alone or RAG for personalized responses?
If responses need to stay grounded in external or frequently updated user data, RAG is usually still important. Long context windows let a model read more text in one prompt, but RAG is specifically designed to pull in relevant external information at answer time. A practical approach is to use long context for broader synthesis and RAG for grounding.
Can a 1M-token context model replace RAG for long academic or medical documents?
Not automatically. Even with a 1M-token context window, RAG remains relevant when you need up-to-date external evidence and better grounding. The source explicitly frames this as an open question (‘Did Google just kill RAG?’) rather than a definitive replacement.
Why do long-context models still miss important details even when the full document is provided?
A larger context window increases how much text can be included, but it does not by itself add external retrieval or source-grounding. RAG addresses a different problem: fetching relevant external information and grounding outputs in it. So ‘more context’ and ‘retrieval grounding’ are complementary, not identical.
What architecture do enterprise teams use when choosing between long context windows and RAG?
A common architecture choice is not either/or: use RAG when answers must be grounded in external data, and use long context windows when a single response must consider more material at once. This aligns with the comparison framing and with how RAG is described as a grounding method rather than just a context-length workaround.
I already have API agents with RAG. When does adding long context windows actually help?
Adding long context windows helps when your agent needs to synthesize more material in one pass. Keep RAG as the grounding layer for external, current information, and use long context to expand what can be considered in a single prompt. In other words: retrieval for evidence, long context for broader synthesis.
Which is faster to production: long-context prompting or a full RAG system?
A full RAG system generally has more setup work because it requires tasks like installing libraries, preparing data, generating embeddings, connecting a database, and creating a vector index. Long-context prompting can be simpler to start, but RAG is designed for grounded answers from external data. Choose based on whether speed-to-start or grounded retrieval is your priority.