That model is now breaking down—not because the information is wrong, but because the interface no longer matches how people work.
Across enterprises, teams are increasingly interacting with legacy documents through conversational interfaces. The underlying files often remain unchanged.
What changes is how people access them. Instead of searching, scrolling, and interpreting, users ask questions and receive synthesized, context-aware responses grounded in those same documents.
This shift is not primarily about better language models. It is about changing the unit of knowledge from “document” to “answer,” and redesigning the systems that govern how answers are assembled, constrained, and verified.
From Static Documents to Dynamic Interactions
The real transition is not OCR or search, but the move from document-level retrieval to fragment-level interaction. In modern systems, documents are decomposed into addressable units—paragraphs, clauses, tables—each enriched with metadata such as version, scope, and applicability.
A conversational layer then assembles answers dynamically from multiple fragments while retaining links back to authoritative sources. In this model, documents act as truth stores.
Conversations become views. The assistant does not own the truth; it composes introducing context aware agents projections from an underlying corpus that remains intact and auditable.
This distinction matters. Without it, conversational systems drift into paraphrasing without accountability. With it, users can move fluidly from a synthesized answer to the exact clause or section that supports it. 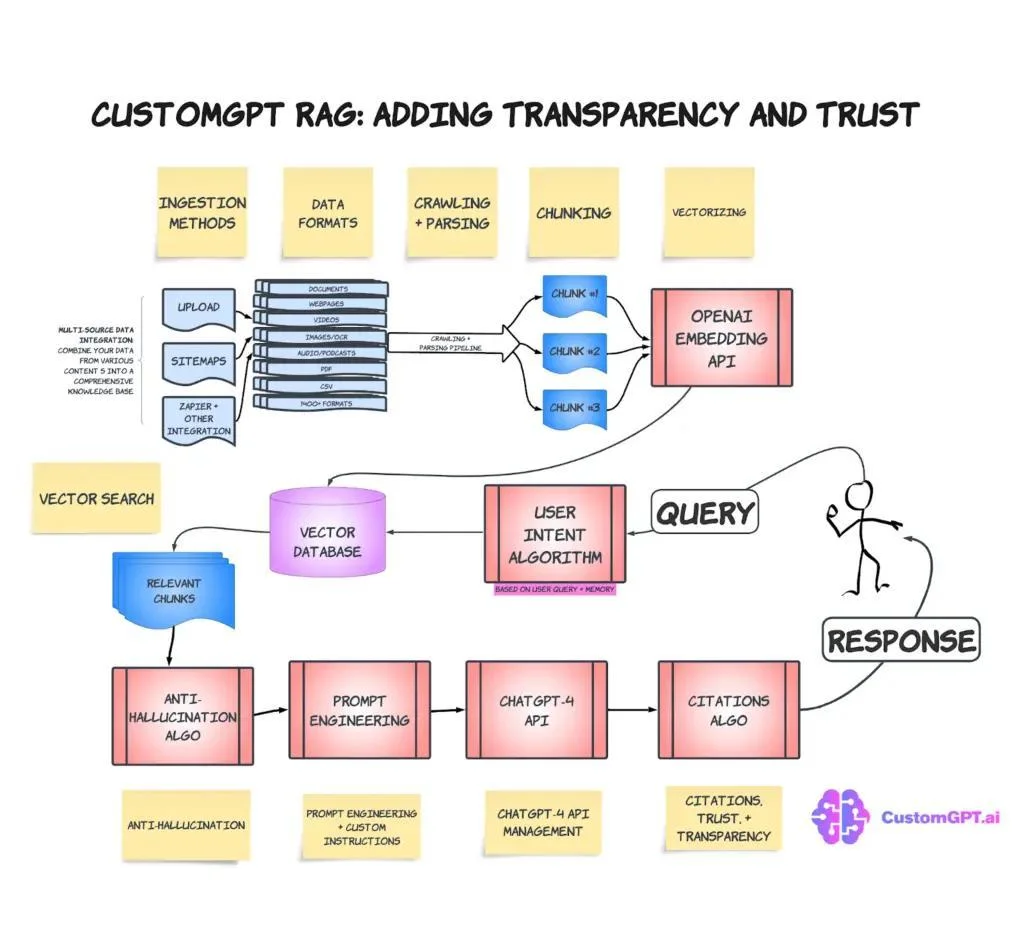
The Role of AI in Transforming Information Access
AI’s impact on information access lies in its ability to turn every fragment of a document into a governed, query-aware answer surface rather than a passive block of text.
Information shifts from something users must search for manually to something that adapts to role, intent, and risk context. The deepest impact is not speed, but adaptability. Modern retrieval-augmented systems often maintain multiple indices.
Under the hood, this requires separating two concerns:
- Semantic relevance: what content matches the question conceptually
- Policy eligibility: what content is allowed for this user, purpose, and moment
Systems that collapse these layers tend to fail quietly—returning plausible but outdated, mis-scoped, or inappropriate information. Systems that keep them distinct can safely scale.
A useful operational framework is to treat each answer as operating within a limited context budget. That budget must be allocated across dimensions such as semantic fit, recency, authority, and risk.
Different use cases weight these dimensions differently: safety procedures emphasize authority and risk, while general information or HR content may emphasize recency.
Core Technologies Behind Conversational Knowledge
Effective AI-driven knowledge delivery depends on treating the stack as a data pipeline rather than a simple “chat on top of PDFs.” Each stage enforces a different kind of precision, from characters to clauses to conversations.
Key layers include:
- Ingestion and recovery
- OCR plus layout-aware parsing to recover usable text from scans and complex layouts
- Structure preservation so downstream systems retain headings, lists, and tables
- Indexing and retrieval
- Dense embeddings to match intent
- A parallel constraint layer to enforce version, scope, and sensitivity
- Retrieval-augmented generation
- Evidence-first assembly from multiple fragments
- Routing that selects strict or exploratory retrieval depending on risk
- Conversation orchestration
- Turn-level decisioning: answer, clarify, branch into a flow, fall back, or refuse
- Mandatory citation and grounding rules enforced before responses ship
The most reliable systems treat retrieval as evidence gathering, not answer selection. Generation becomes constrained composition over vetted material, rather than free-form text creation.
This is why many failures attributed to “hallucinations” are actually failures of retrieval control and governance.
Optical Character Recognition and Text Extraction
High-value OCR is less about recognizing characters than about reconstructing document intent, as in intelligent document processing.
Paragraph boundaries, table structures, headers, and footnotes must be preserved so that downstream systems can answer granular questions without mixing versions or violating compliance constraints.
Conversational agents require not just text but a map of where that text lived, which clause it belonged to, and how it related to surrounding content.
Modern pipelines therefore use multi-stage extraction: visual segmentation to identify regions such as tables or sidebars, language models to validate text against domain vocabularies, and layout graphs that encode reading order and hierarchy.
Evaluating OCR quality requires more than character error rates. Logical unit preservation—whether clauses, rows, or bullet items remain intact—is often a more meaningful metric, since a single broken list item can corrupt downstream answers.
Semantic Search and Retrieval-Augmented Generation
The dividing line between basic semantic search and production-grade RAG lies in how retrieved passages are treated. In robust systems, retrieved text is evidence, not an answer.
- Semantic similarity is only a first pass.
- Candidate passages are filtered again using constraints like version validity, audience scope, and sensitivity.
- Evidence is assembled, not cherry-picked.
- Definitions, exceptions, and procedures may be bundled so the generator can reason across linked clauses without inventing missing links.
- Retrieval tiering reduces misapplication.
- High-risk queries use strict policy-filtered retrieval.
- Exploratory queries can use a recall-heavy tier, selected by routing logic.
Conversational Interfaces and Source-Linked Citations
The full value of conversational interfaces emerges when every turn is treated as a testable claim backed by source-linked citations rather than free-form text.
- Span-level grounding
- Each clause in the answer aligns to a specific source span plus metadata such as document identifier, version, and access scope.
- Verification before response
- Systems can block uncited statements and prevent mixing incompatible versions.
- Citations as usability
- Inline clause-level citations reduce validation time because users can jump from a contested sentence to the exact fragment.
Transforming PDFs into Queryable Knowledge Bases
The key inflection point in transforming PDFs is not uploading files but decomposing them into addressable knowledge objects such as clauses, fields, and tables, each with stable identifiers. Queries then target entities rather than fishing through text.  A mature PDF knowledge base behaves less like a document store and more like a versioned, queryable schema. When indexing treats governance as a first-class dimension, PDFs cease to behave like flat text stores and instead act as governed query surfaces for conversational systems.
A mature PDF knowledge base behaves less like a document store and more like a versioned, queryable schema. When indexing treats governance as a first-class dimension, PDFs cease to behave like flat text stores and instead act as governed query surfaces for conversational systems.
Citations, Grounding, and Trust
Conversational interfaces create trust when they make provenance visible. High-confidence systems ground responses at the clause or span level, not just at the document level.
Each factual statement can be traced back to a specific source, version, and scope. This enables fast validation and meaningful human oversight. End-of-answer reference lists are easy to implement but hard to audit.
Inline, granular citations require more orchestration, but they dramatically reduce review effort in regulated or high-stakes domains. The goal is not to prove the model is smart, but to make it easy for a human to verify why an answer should be trusted.
Interactive Experiences Beyond Q&A
The most effective conversational experiences are not just responsive; they are directional. Instead of answering and stopping, strong systems guide users through short, purposeful paths: clarify intent, validate applicability, surface evidence, suggest next steps.
Each turn is deliberate. This requires turn-level state management and simple decision logic layered on top of retrieval. The result feels less like “chatting” and more like navigating a well-designed workflow—without hiding the underlying documentation.
Creating Interactive User Experiences
The most significant shift in user experience lies not in the chat interface itself but in turn-level orchestration. After each user message, the assistant decides whether to answer, clarify, branch into a flow, or trigger an action.
- Turn-level routing
- Decisions are driven by intent, confidence, and horizon.
- Conversation blueprints
- High-value paths can be pre-defined: understand policy → validate applicability → generate summary → export evidence.
- Workflows, not just chats
- Users move from answers to related artifacts without losing traceability to source documents.
Governance and Ethical Considerations
Governance failures rarely stem from obvious hallucinations. They occur when organizations cannot demonstrate why an answer was trusted. Treating each conversational turn as a regulated data transaction with provenance addresses this gap.
- Accuracy and attribution
- Each sentence should resolve to a specific clause, effective date, and accountable owner.
- End-of-message references are insufficient when disputes hinge on exact wording or version.
- Privacy and bias
- Protection depends on end-to-end controls: role-aware retrieval, constrained prompting, and careful logging practices.
- Bias and profiling risks often arise from retrieval and recombination rather than from a single document.
Without embedding accuracy, attribution, privacy, and bias controls into the same orchestration layer that delivers conversational access, productivity gains can become compliance liabilities.
Advanced Applications and Future Directions
Multi-document knowledge graphs lift entities, relationships, and temporal constraints out of PDFs into governed networks. Graph-enriched retrieval supports reasoning over chains such as asset → component → constraint rather than flat text.
The value lies in consistency enforcement: typed edges encode precedence, dependency, or conflict, enabling systems to detect incompatible guidance before generation.
Constraint-centric graph designs support queries about applicability and interaction across documents and timeframes. Enterprise-grade conversational AI ultimately depends on treating every generated sentence as a regulated object with provenance.
Span-level grounding, policy evaluation, and oversight logging form a control plane that supports auditability and replay.
Conclusion
The move from PDFs to conversations is not simply a UI upgrade. It is a structural shift from document-level consumption to fragment-level delivery, where retrieval, governance, and orchestration determine what a user can see, rely on, and prove.
In this emerging model, documents remain truth stores, while conversational interfaces become views—context-aware projections grounded in governed evidence.
The systems that succeed are those that treat retrieved text as evidence, enforce scope and version constraints before generation, and make every response traceable at the sentence or span level.
When this control plane is built into the same layer that delivers conversational access, PDFs stop behaving like static archives and start operating as auditable, workflow-ready knowledge surfaces.
Upgrade Knowledge Delivery With AI
Move from static documents to AI-powered knowledge delivery that answers in real time.
Trusted by thousands of organizations worldwide


Frequently Asked Questions
Do I need to split or clean up 200-page PDFs before uploading them to an AI knowledge base?
Usually not. In a document-grounded knowledge system, long files are broken into smaller addressable units such as paragraphs, clauses, and tables, so you can typically upload a 200-page PDF as one file if it is machine-readable and under the 100MB file limit. Clean up the file first only when the PDF is image-only, has poor text extraction, or contains unreadable tables.
Can scanned or old PDF archives really be turned into searchable conversations?
Yes, if the files contain extractable text. Conversational retrieval works by indexing document fragments and returning grounded answers from that indexed text, so older or scanned PDFs can become searchable once OCR or another text-extraction step makes the content readable. After that, you can ingest the material as PDFs, URLs, or other supported formats and use citations to verify the source behind each answer.
What makes a document-based knowledge assistant different from uploading the same PDFs to ChatGPT or Claude?
The key difference is the retrieval system around the model. A document-based knowledge assistant keeps a persistent index of your corpus, breaks documents into smaller fragments, tracks metadata such as version and scope, and returns answers with citations so you can verify them. Brendan McSheffrey of The Kendall Project said, u0022We love CustomGPT.ai. It’s a fantastic Chat GPT tool kit that has allowed us to create a ‘lab’ for testing AI models. The results? High accuracy and efficiency leave people asking, ‘How did you do it?’ We’ve tested over 30 models with hundreds of iterations using CustomGPT.ai.u0022 For teams, that turns a one-off file chat into a repeatable knowledge delivery system.
How do citations and source links reduce hallucinations when AI answers from PDFs?
Citations reduce hallucination risk by letting you inspect the exact paragraph, clause, or document behind an answer instead of trusting a summary on its own. That matters most when content is long, frequently updated, or spread across multiple files. Tumble Living used conversational support to deflect hundreds of tickets with 24/7 coverage, and Rachel Chen said customers were u0022receiving the exact same information.u0022 Source links help create that kind of consistency because users can verify what the assistant relied on.
Can conversational access to PDFs actually shorten onboarding and training time?
Often yes. Instead of reading full manuals from start to finish, new team members can ask for the exact policy, workflow, or example they need in the moment. Stephanie Warlick described the value this way: u0022Check out CustomGPT.ai where you can dump all your knowledge to automate proposals, customer inquiries and the knowledge base that exists in your head so your team can execute without you.u0022 In practice, conversational access turns static documents into an on-demand answer layer, which can reduce interruptions and help people ramp faster.
Can a document-based knowledge assistant work inside Slack or Teams?
Yes. If your workspace can connect through an API or an integration layer, the knowledge assistant can sit behind Slack, Teams, or another chat surface while the documents remain the governed source of truth. Bill French said, u0022They’ve officially cracked the sub-second barrier, a breakthrough that fundamentally changes the user experience from merely ‘interactive’ to ‘instantaneous’.u0022 For users, that means the chat app is just the interface; the bigger requirement is keeping the underlying knowledge base current, grounded, and properly cited.
Related Resources
These guides expand on the workflows and concepts behind AI-powered knowledge delivery.
- AI Document Analysis — Learn how AI can extract insights, organize information, and make complex business documents easier to search and use.
- Custom AI Knowledge Base — See how a tailored AI knowledge base helps teams deliver faster, more accurate answers with CustomGPT.ai.
- Conversational AI Vs Chatbots — Understand the differences between conversational AI and traditional chatbots so you can choose the right experience for your users.

Arooj Ejaz is the Marketing Operations Lead at CustomGPT.ai, where she works on content, growth operations, and go-to-market programs for AI agent and chatbot solutions.