For nearly three years, our engineering team chased one goal: sub-second performance. Every optimization, every system tweak, every millisecond we could shave off was a step toward making AI interaction feel instant.
Today, that mission is complete.
We’re thrilled to announce that CustomGPT.ai has achieved sub-second query speed — and with it, a new milestone for enterprise-grade AI.
The Breakthrough: Instant Answers, Every Time
Powered by OpenAI’s Priority Processing — now including the newly upgraded GPT-4o-mini Priority interpretation and classification services — and our custom speed-optimized infrastructure, CustomGPT.ai agents now respond faster than you can blink.
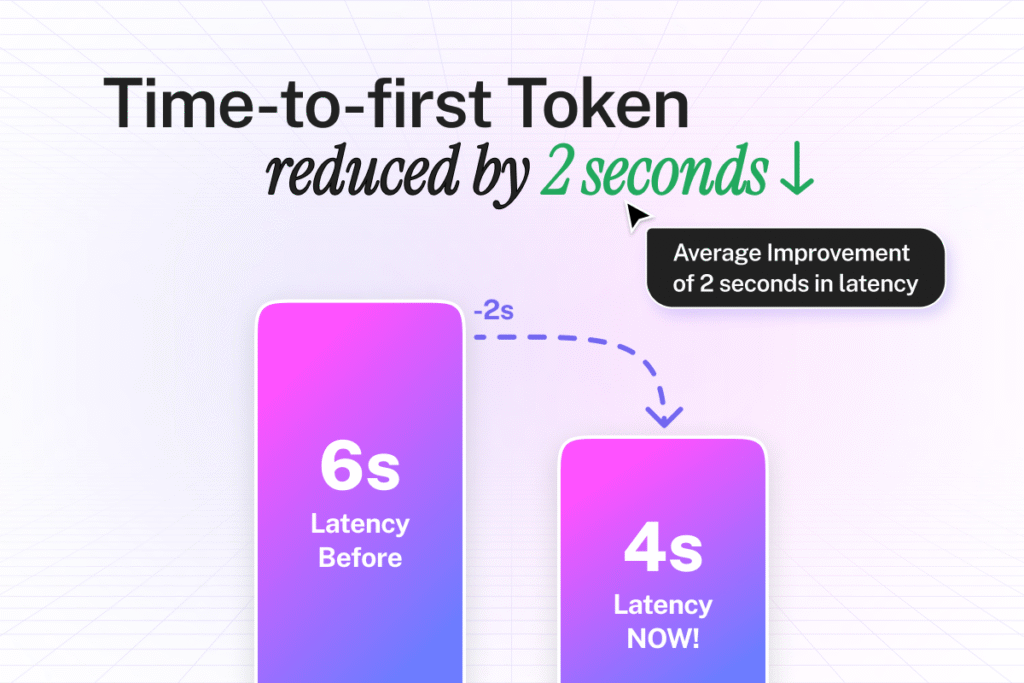
These improvements deliver up to 2 seconds of additional latency gain across the entire system.
Best of all: this upgrade is automatically enabled for all accounts (except those running Azure).
Sub-second performance is now available to everyone using our speed-optimized mode.
And for Enterprise customers, it gets even better.
Introducing Priority Queries — automatic priority processing for every single query you run. Not limited to models or configurations, every request you send now jumps to the front of the line.
The result?
- Time-to-first-token drops from 6 seconds to 4 seconds.
- Average latency improves by up to 2 seconds across all interactions.
- Background classification and query interpretation now run on GPT-4o-mini Priority, increasing throughput across all agents
- Fastest Responses are now virtually instant
- Numeric Search is now optimized so that queries without alphanumeric codes incur zero added latency
No setup required. No additional cost. It’s already live in your account.
Why Speed Matters: Every Millisecond Is Money
In AI, every millisecond matters and numbers don’t lie.
According to Google’s research, each extra second of delay leads to exponentially higher abandonment rates. When your AI hesitates, prospects leave, support tickets escalate, employees give up, and conversion rates tank.
When it responds instantly, everything changes.
Employees find critical information without breaking their workflow.
- Conversations flow naturally.
- Sales teams close deals in real time.
- Support resolves complex issues in single interactions.
Speed isn’t a nice-to-have — it’s the difference between AI that accelerates your business and AI that frustrates your users.
Built for Teams That Move Fast
Enterprise means teams — and teams need tools that work for everyone, from the CEO to the newest support agent.
CustomGPT.ai for Teams gives organizations the control, flexibility, and speed they need to scale:
- Add seats as you grow — from 5 to 500 and beyond.
- Chat-only roles for front-line reps without exposing backend configurations.
- Per-agent access controls so each department gets its own tailored agent.
- Custom SSO integration for seamless, secure authentication.
With Priority Queries active across every seat, your entire team now runs at maximum velocity — no lag, no waiting, no friction.
Bring All Your Data Into One Intelligent System
Your knowledge lives across SharePoint, Confluence, Google Drive, Zendesk, and Notion. Enterprise plans include auto-sync for all of them — connect once, and your agent stays up to date with every edit, ticket, and update.
PDFs With Proof
Enterprise customers get the PDF Viewer with Smart Highlighting. Your agent cites a PDF, the user clicks it, and sees the exact text highlighted in the actual document. No hunting through pages. No control-F searching.
The relevant section is right there, highlighted, in context.
When your AI cites a source, users can see the exact section highlighted in the document itself — building trust and cutting support requests.
Total Control Over Your AI’s Brain
Every business has unique needs. Enterprise gives you the controls to tune your agent exactly how you need it:
- AI Model Selector – Switch between GPT-4.1, GPT-4o, Claude Opus, Claude Sonnet, and more.
- Extended Context Windows – Handle longer conversations and more complex queries without losing the thread.
- Extended History Windows – Your agent remembers more of the conversation, making multi-turn interactions feel natural.
- Extended Persona Length – Build detailed, nuanced personas that truly represent your brand voice and expertise.
- Extended End-User Prompt Length – Let users ask complex, detailed questions without hitting character limits.
And all of it runs on Priority Queries for instant responses no matter how complex your configuration.
Scale Without Limits
Modern enterprises need systems that grow as fast as they do. CustomGPT.ai’s Enterprise infrastructure scales effortlessly:
Enterprise plans scale with you:
- Uncapped queries – Metered but never blocked. Your AI never goes down during a traffic spike.
- Unlimited agents – One agent per product line? Ten agents for different departments? Build as many as you need.
- Massive storage limits – Extend word storage and document storage to handle your entire knowledge base.
- Increased processing capacity – Process millions of words per month. Ingest thousands of documents. Upload gigabytes of images.
- Custom API rate limits – Need 500 requests per minute? 1,000? We’ll configure it for your workload.
Your business grows. Your AI grows with it.
Enterprise Means Trust
Speed and scale mean nothing without reliability. That’s why our Enterprise offering includes:
- Full DPA coverage for compliance and security.
- Azure as AI Model Provider for customers who need a controlled environment. (Note: Priority Queries will be available for Azure customers once Microsoft adds Priority processing support. Azure customers can switch to OpenAI for immediate access.)
- Unlimited analytics history — because long-term insight matters.
- Dedicated support channels that truly prioritize your business.
Join the Community
See how other Enterprise customers are using Priority Queries and advanced features.
Join the CustomGPT.ai Slack Community to connect with teams pushing the boundaries of AI agents.
Build a Custom GPT for your business, in minutes.
Drive revenue, save time, and delight customers with powerful, custom AI agents.
Trusted by thousands of organizations worldwide


Frequently Asked Questions
What are Priority Queries, and do I need to turn them on manually?
Priority Queries are automatic priority processing for Enterprise queries, so you don’t need to change prompts, models, or configurations. The rollout is automatically enabled, with Azure deployments called out as an exception.
How can I verify that Priority Queries are live for my team?
Start by confirming your workspace is Enterprise and not on Azure, since Azure is explicitly excluded from this rollout. Then compare response latency before and after enablement, especially if you use speed-optimized mode, where sub-second performance is highlighted.
Why do some answers still feel slow even after sub-second Priority Queries?
The announcement describes latency improvements as ‘up to 2 seconds,’ which means results can vary by query. Sub-second performance is specifically tied to speed-optimized mode, and Azure deployments are excluded from this rollout.
Do Priority Queries help only chat, or also automated workflows like email and ticketing?
Priority Queries are described as applying to ‘every single query’ and ‘every request,’ which implies they can help both live chat and API-driven automation flows—as long as those flows are sending queries through the same system.
Do Priority Queries improve answer quality, or just response speed?
The launch message focuses on speed and latency reduction (including sub-second performance and up to 2 seconds of latency gain). It does not claim a direct increase in answer quality.
How do Priority Queries compare with alternatives like Azure OpenAI, OpenAI Scale Tier, or self-hosted vLLM?
No direct benchmark comparison is provided in the announcement. What is clearly stated is that Priority Queries are automatic for Enterprise, apply across requests rather than specific model settings, and exclude Azure-based deployments in this rollout.