We are proud to confirm that our system has outperformed existing methods, establishing a new state-of-the-art for agent harnesses on the GAIA benchmark.
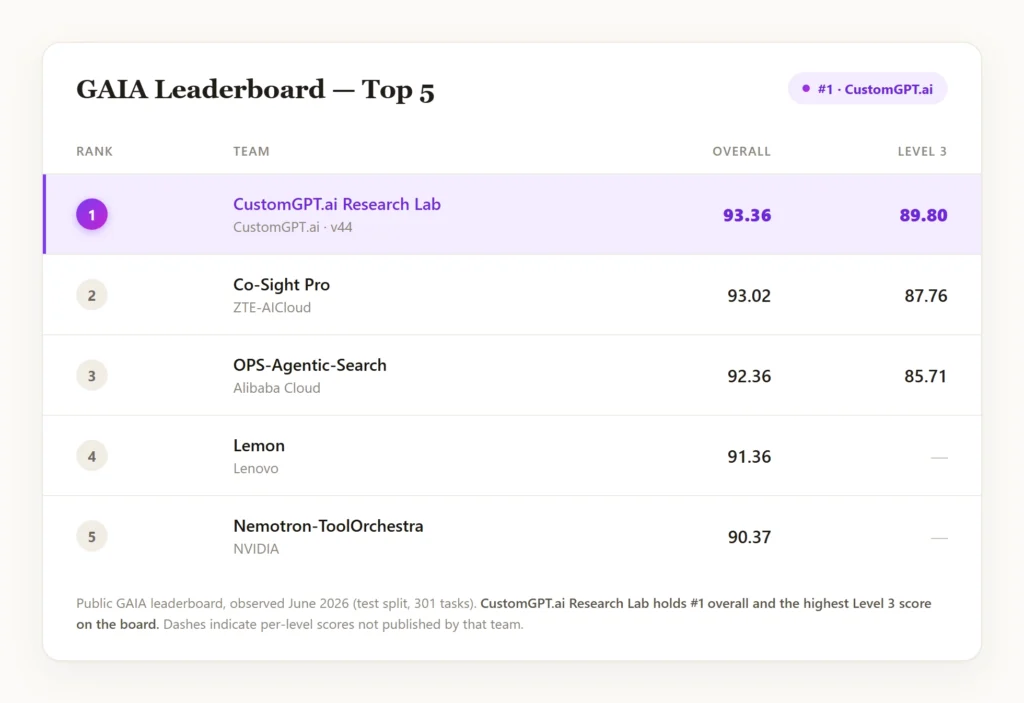
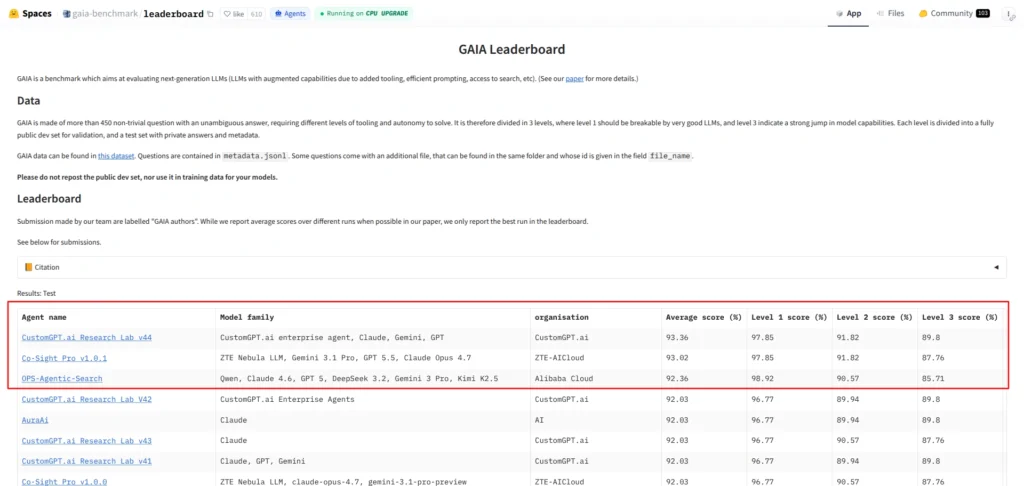
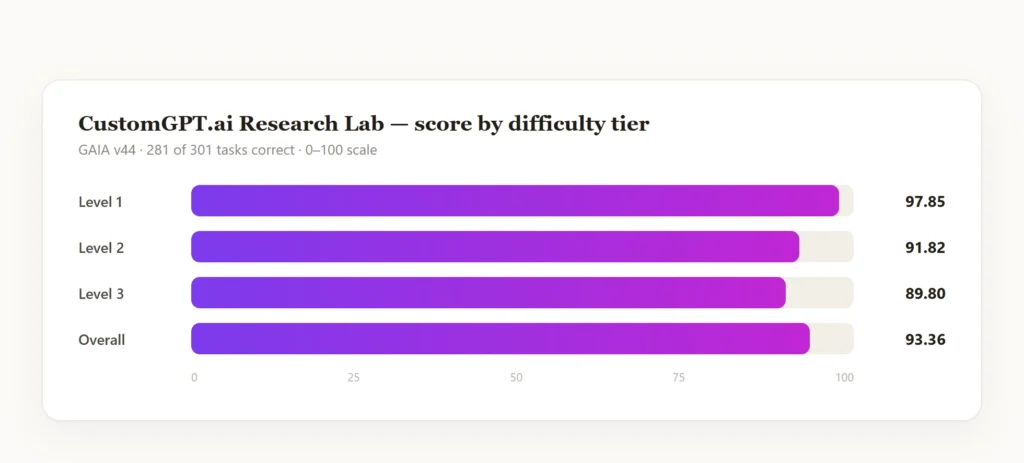
As of today (June 2026), CustomGPT.ai Research Lab holds the top position on GAIA, with an overall score of 93.36% (281 out of 301 tasks on the held-out private test set, scored by the GAIA maintainers). It also leads on Level 3, the benchmark’s hardest tier, at 89.80%.
What is GAIA?
GAIA, built by Meta-FAIR, Hugging Face, and AutoGPT, tests something most benchmarks do not: whether an AI system can complete real-world tasks end to end, the kind that require planning, browsing the web, using tools, reading documents, and recovering when something fails.
When it was introduced, capable humans scored about 92% and the strongest AI systems of the day scored about 15%. Today’s benchmark run of our agent harness crossed 93% on this benchmark.
What we did
Our tiny research team of fewer than six AI engineers used widely available frontier models from Anthropic Claude and OpenAI to build an agent harness around key constitutional principles, to solve the hardest GAIA problems.
We did not train a model of our own, and the labs ranked just behind us are research groups at some of the largest technology companies in the world.
The total cost of the research initiative was about $30,000 over five months — roughly $23,000 in engineering time and $7,000 in inference across all experimentation and runs, with each of the six engineers equipped with Claude Code (Max Plan).
Because GAIA’s test answers are held private, our system is blocked from the benchmark’s own datasets, and no answer is submitted until the harness has executed live tools – web search, code, document parsing, live APIs – to obtain it. The results reflect the harness doing the work end to end, not recalling a key.
Why we succeeded
The capability of the agent came not from a bigger model, but from using a better meta-harness, built on top of key constitutional principles. We used ordinary, publicly available models, Claude for reasoning, Gemini for vision, Code execution, and we built the system around them. We built our meta harness around three key principles.
- Verification: Assume that every LLM is wrong by default. A quadruple-verification framework is applied across the agent’s decision-making and input/output process — every action, every API call, every decision, every artefact generated. Trust nothing.
- Resilience: Every external dependency sits behind a cascade of fallbacks, so a single dead page or a tool that returns nothing does not end the task. The system takes the next path and keeps going. A simple action like fetching a web page needs a 7-layer cascade to make it resilient.
- Tool Use: An agent harness is as good as the set of tools and context it has access to. Equipping the agent harness with a wide swathe of tools like Google Vision, Google Scholar and other best-in-class APIs greatly improves the ability of the agent harness to complete difficult tasks.
The harness is provider-agnostic. It lifts whichever underlying model it runs on.
Methodology
– Submission: CustomGPT.ai Research Lab agent harness
– Benchmark: GAIA private held-out test set
– Date observed: June 2026
– Score: 93.36% overall, 281 / 301 tasks
– Hardest tier: 89.80% on Level 3
– Model stack: Publicly available frontier models, including Claude for reasoning, Gemini for vision, and OpenAI models where useful
– Tooling: Live web search, code execution, document parsing, OCR/vision, Google Scholar, live APIs, and fallback retrieval tools
– Data access: Private GAIA answers were not accessible to the harness
– Scoring: Results scored by the GAIA benchmark maintainers
– Training: No custom model was trained; the result came from the agent harness, verification system, resilience layer, and tool-use architecture
Want to test benchmark-informed agents on your own enterprise workflows?
Start with Plan and Act Enterprise Agents, or schedule a CustomGPT.ai Enterprise discussion.
See for yourself
The full architecture, the model stack, and how the system is built are in our public repository: https://github.com/adorosario/customgpt-agent
What’s next
CustomGPT.ai Plan and Act Enterprise Agents are already in beta access. Over the next few weeks, we are incorporating the key learnings from this GAIA research initiative into that production system: stronger verification loops, deeper tool-use patterns, and more resilient recovery paths when web pages, APIs, files, or intermediate reasoning steps fail.
The goal is straightforward: bring the same agent-harness principles that produced this GAIA result into real enterprise workflows, where accuracy, traceability, and reliability matter more than demos.
FAQ
What did CustomGPT.ai achieve on GAIA?
CustomGPT.ai Research Lab reached 93.36% overall on the GAIA benchmark, solving 281 of 301 tasks on the held-out private test set. The result placed CustomGPT.ai Research Lab at #1 on the GAIA leaderboard as observed in June 2026.
What is GAIA?
GAIA is a benchmark for General AI Assistants created by Meta-FAIR, Hugging Face, and AutoGPT. It evaluates whether AI systems can complete real-world, multi-step tasks that require reasoning, web browsing, tool use, document understanding, and answer verification.
Why is GAIA important for evaluating AI agents?
GAIA is important because it tests whether an AI system can complete tasks end to end, not just answer isolated questions. Many GAIA tasks require planning, searching the web, reading files, using tools, checking sources, and recovering from failed attempts.
What score did CustomGPT.ai get on GAIA?
CustomGPT.ai Research Lab scored 93.36% overall on GAIA, with 281 correct answers out of 301 private test tasks. The level breakdown was 91/93 on Level 1, 146/159 on Level 2, and 44/49 on Level 3.
What was CustomGPT.ai’s Level 3 score on GAIA?
CustomGPT.ai Research Lab scored 89.80% on GAIA Level 3, solving 44 of 49 tasks. Level 3 is GAIA’s hardest tier and is designed to test more difficult long-horizon reasoning, tool use, and recovery behavior.
Did CustomGPT.ai train a new AI model for this result?
No. CustomGPT.ai did not train or fine-tune a new model for this result. The score came from an agent harness built around widely available frontier models, verification, resilience, and tool use.
What is an agent harness?
An agent harness is the system around an AI model that lets it plan, use tools, verify work, recover from failures, and complete tasks. In practice, the harness determines how the model searches, reads, calls APIs, writes code, checks evidence, and decides when an answer is ready.
Why does the agent harness matter?
The agent harness matters because modern AI agent performance depends on more than the base model. A strong harness can make an ordinary frontier model more reliable by forcing verification, adding tools, retrying failed paths, and grounding answers in external evidence.
Was this result caused by a bigger model?
No. The result was driven by the harness, not by training a larger model. CustomGPT.ai used public frontier models and focused the research effort on the surrounding architecture: verification, resilience, tool routing, and recovery.
Which models did CustomGPT.ai use?
The system used widely available frontier models, including Claude for reasoning, Gemini for vision, and OpenAI models where useful. The important design choice was not a single model, but a provider-agnostic harness that can lift the performance of the models it runs on.
What does provider-agnostic mean?
Provider-agnostic means the harness is designed to work across model providers instead of being locked to one model vendor. The agent architecture can route work to different models and tools depending on the task.
What are the three core principles behind the harness?
The harness is built around verification, resilience, and tool use. Verification assumes every model output may be wrong, resilience keeps the agent moving when tools or sources fail, and tool use gives the agent access to the external systems needed to solve real tasks.
What does verification mean in this agent harness?
Verification means the harness checks the agent’s work before accepting an answer. Instead of trusting a model’s first response, the system validates intermediate steps, tool outputs, source evidence, API results, and final answers.
What does resilience mean in this agent harness?
Resilience means the harness does not stop when one source, page, API, parser, or tool fails. The system uses fallback paths so the agent can keep working through dead links, missing data, unreliable pages, and incomplete tool outputs.
What does tool use mean in this agent harness?
Tool use means the agent can call external systems to gather and verify information. These tools include web search, code execution, document parsing, OCR and vision, Google Scholar, live APIs, and fallback retrieval tools.
How did CustomGPT.ai reduce the risk of memorization?
CustomGPT.ai reduced memorization risk by using the held-out private GAIA test set, blocking access to benchmark datasets and answer sources, and requiring live tool execution before submitting answers. The result reflects the harness doing work at runtime, not simply recalling a public answer key.
Are GAIA test answers public?
No. The GAIA private test answers are held out and scored by the GAIA maintainers. CustomGPT.ai reports the private test-set score, not a public validation-set score.
Who scored the GAIA result?
The result was scored by the GAIA benchmark maintainers on the held-out private test set. CustomGPT.ai did not self-grade the final leaderboard score.
How many people worked on this research initiative?
The research initiative was completed by a small CustomGPT.ai research team of fewer than six AI engineers. The team focused on harness engineering rather than training a new model.
How much did the GAIA research initiative cost?
The total research initiative cost was about $30,000 over five months. That included roughly $23,000 in engineering time and about $7,000 in inference across experimentation and benchmark runs.
Why is this result relevant to enterprises?
This result is relevant to enterprises because GAIA-style tasks resemble real knowledge work: multi-step research, document analysis, source checking, tool use, and recovery from incomplete information. Those are the same reliability challenges production enterprise agents need to solve.
Is this just a benchmark result, or will it affect the product?
This is not just a benchmark result. CustomGPT.ai is incorporating the learnings from the GAIA research initiative into its production Plan and Act Enterprise Agents over the next few weeks.
Are CustomGPT.ai Plan and Act Enterprise Agents available now?
Yes. CustomGPT.ai Plan and Act Enterprise Agents are already available in beta as a self-service product. The GAIA research learnings are being folded into the production system as the beta evolves.
How will GAIA research improve CustomGPT.ai Enterprise Agents?
The GAIA research will improve CustomGPT.ai Enterprise Agents through stronger verification loops, more resilient recovery paths, and deeper tool-use patterns. These improvements are intended to make agents more reliable on real enterprise workflows.
What is the relationship between this harness and CustomGPT.ai’s RAG platform?
The agent harness complements CustomGPT.ai’s RAG-as-a-Service platform. RAG provides grounded access to enterprise knowledge, while the agent harness adds planning, tool use, verification, and recovery around that knowledge.
Can customers use the exact GAIA research harness today?
Customers can use CustomGPT.ai Plan and Act Enterprise Agents today in beta, and the GAIA learnings are being incorporated into that production system. The benchmark system and the production system are not positioned as separate demos; the research is feeding directly into product improvements.
What kinds of enterprise workflows can benefit from this agent harness?
Enterprise workflows that require multi-step reasoning, document analysis, research, support operations, compliance review, and knowledge work can benefit from this harness. The strongest fit is work where accuracy, traceability, source grounding, and failure recovery matter.
Does this mean CustomGPT.ai has achieved AGI?
No. A strong GAIA score does not mean AGI. It means the system performed extremely well on a specific benchmark for tool-using general AI assistants.
Does beating the human baseline on GAIA mean the agent is better than humans?
No. Crossing the reported human baseline on GAIA means the system performed strongly on GAIA’s task distribution. It does not mean the system is better than humans in general or across all forms of work.
Is GAIA a perfect benchmark?
No benchmark is perfect. GAIA is valuable because it tests real-world tool use and multi-step task completion, but leaderboard results should still be interpreted as evidence for a specific task distribution, not as a universal measure of intelligence.
Is the CustomGPT.ai GAIA result reproducible?
The architecture, model stack, and system design are available in the public repository, but exact leaderboard reproduction can vary because GAIA tasks involve live web data, model nondeterminism, and tool availability. The important reproducible contribution is the harness architecture and operating principles.
Where can readers see the architecture?
Readers can review the public repository for the architecture, model stack, and implementation details. The repository is available at https://github.com/adorosario/customgpt-agent.
What should readers do next?
Readers who want to use these capabilities can start with CustomGPT.ai Plan and Act Enterprise Agents. Teams planning larger enterprise deployments can schedule a CustomGPT.ai Enterprise discussion.
Start using Enterprise Agents
CustomGPT.ai Plan and Act Enterprise Agents are already available in beta as a self-service product. If your team wants to test benchmark-informed agents on real enterprise workflows, you can Start Using Enterprise Agents.
If your team wants help mapping Plan and Act Enterprise Agents to a larger production workflow, schedule a CustomGPT.ai Enterprise discussion.

Founder @ CustomGPT.ai , Husband & Father of 4, Avid cricket wicket-keeper