
For the last few years, AI progress has often been measured by how well models perform on exams.
Benchmarks like:
- Can a model pass the bar?
- Can it solve graduate-level science questions?
- Can it answer coding problems?
- Can it reason through math competitions?
Those benchmarks matter. They tell us something important about model intelligence.
But they do not answer the question most enterprises now care about:
Can this AI system actually get work done?
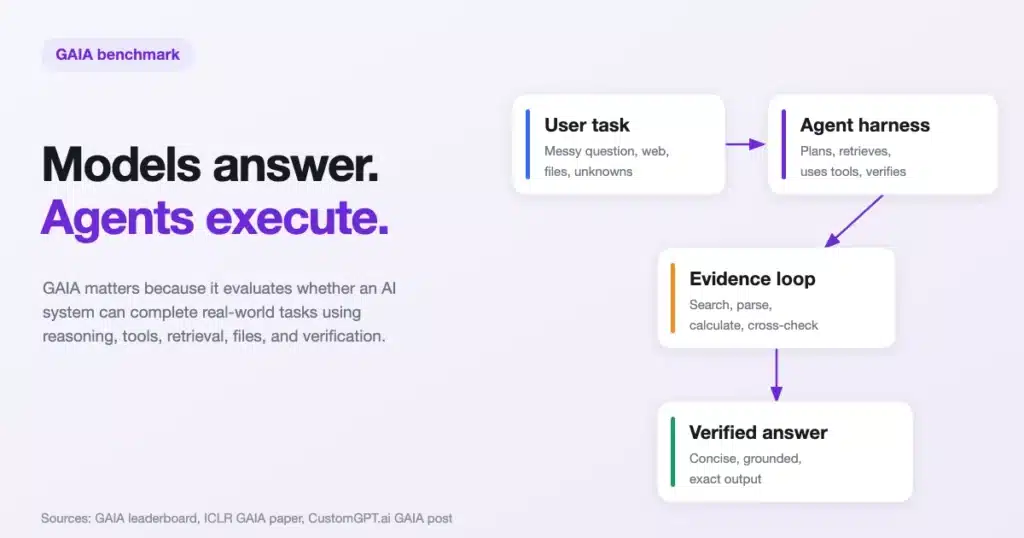
That is the question behind GAIA, one of the most important benchmarks for evaluating general AI agents.
GAIA was introduced as a benchmark for “General AI Assistants” by researchers from Meta-FAIR, Hugging Face, AutoGPT, and others. Its goal is not to test whether a model can answer isolated trivia or perform well on a static exam.
Its goal is to test whether an AI system can complete real-world tasks that require reasoning, web browsing, multimodal understanding, tool use, and precise answer generation. The benchmark was accepted at ICLR 2024 and is now maintained through Hugging Face’s GAIA benchmark infrastructure.
That distinction matters.
A chatbot answers. An agent investigates. A production AI system has to do both, reliably.
Why GAIA Was Created
The motivation behind GAIA is simple: AI benchmarks had started to drift away from the messy reality of knowledge work.
Modern language models were beginning to outperform humans on specialized tests in areas like law, chemistry, medicine, and coding. But those same systems could still fail at tasks a reasonably capable person could solve with a browser, a calculator, a document viewer, and persistence.
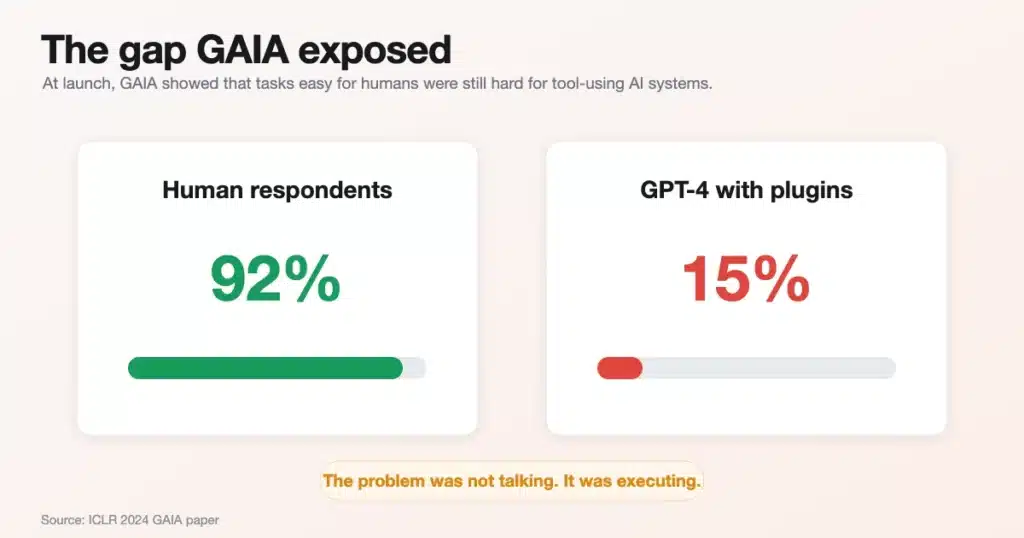
The GAIA authors pointed directly at this gap. In the original paper, humans scored about 92% on GAIA, while GPT-4 with plugins scored about 15%. Models were becoming impressive on formal tests, but they were still weak at robust, tool-using assistant behavior.
This is exactly the problem enterprises run into with AI agents.
A demo looks magical when the question is clean, the answer is obvious, and the data is already in the prompt.
Production is different.
In production, the agent has to search across incomplete information. It has to read files. It has to decide which source to trust. It has to recover when a link is broken, a tool fails, an API response is malformed, or a document contains conflicting information. It has to avoid hallucination.
It has to know when it has enough evidence to answer. And it has to return the answer in the exact format the workflow requires.
GAIA was created to test that kind of capability.
Not “can the model talk?”
But:
Can the system execute?
What GAIA Actually Tests
The official GAIA leaderboard describes the benchmark as evaluating “next-generation LLMs” with augmented capabilities such as tooling, prompting, search, and autonomy. It contains more than 450 non-trivial questions with unambiguous answers and is divided into three levels of difficulty.
Level 1 is intended to be solvable by very strong LLM systems, while Level 3 is designed to require a much stronger jump in agent capability.
That “unambiguous answer” part is important.
GAIA is not asking for long essays. It is not rewarding confident prose. It is not impressed by a plausible explanation.
It usually wants a specific answer: a name, a number, a date, a short phrase, a count, a file-derived result, or some other precise output.
To get there, the agent often needs to perform several steps:
- Understand the user’s question.
- Identify what information is missing.
- Decide which tools to use.
- Search the web or inspect a provided file.
- Parse documents, images, spreadsheets, audio, or other data.
- Cross-check evidence.
- Run calculations or code when needed.
- Recover from dead ends.
- Produce a final answer in the required format.
Some GAIA questions include additional files. The benchmark’s dataset documentation shows that some tasks require working with attached files, not just plain-text prompts.
That means GAIA is closer to real knowledge work than many traditional benchmarks.
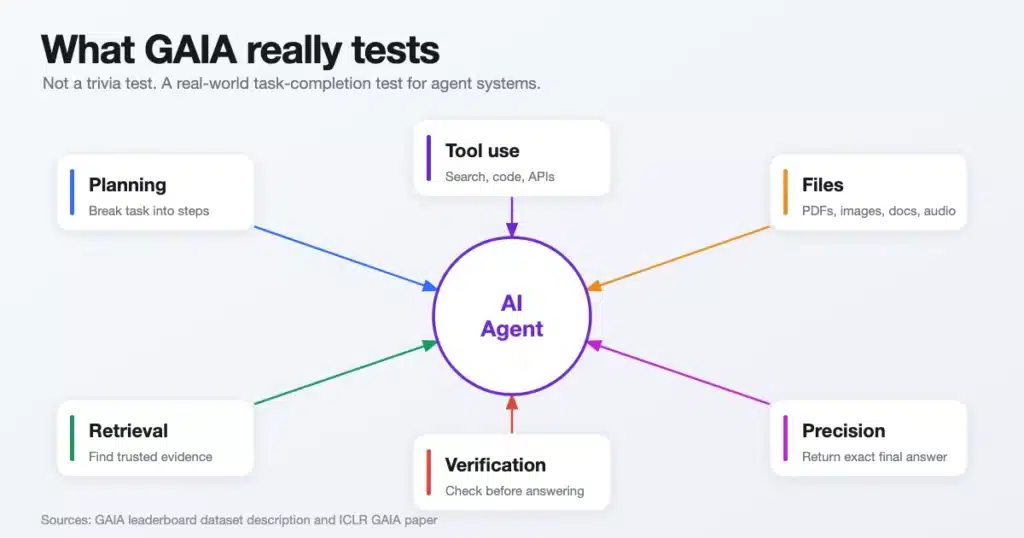
It tests capabilities such as:
- Planning: Can the agent break a task into steps?
- Tool use: Can it use the right tools at the right time?
- Retrieval: Can it find relevant information instead of guessing?
- Multimodal understanding: Can it work with files, images, documents, audio, and structured data?
- Verification: Can it check whether the answer is actually supported?
- Resilience: Can it recover when the first path fails?
- Precision: Can it return the exact final answer, not a vague explanation?
This is why GAIA matters.
It is not just a model benchmark. It is an agent-system benchmark.
GAIA Task Example
Here’s one of the hardest questions on the test. Read it slowly:
“Which of the fruits shown in the 2008 painting ‘Embroidery from Uzbekistan’ were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film ‘The Last Voyage’? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o’clock position.”
Find the painting. Identify every fruit in it. Figure out which ocean liner was used as a prop in that film. Dig up that ship’s breakfast menu from October 1949. Cross-reference the two. Then sort the answer clockwise from 12 o’clock.
One wrong step anywhere, and the whole answer is wrong.
Why Traditional Benchmarks Are Not Enough
Traditional LLM benchmarks are useful, but they often test the model in isolation.
The model receives a prompt. The model outputs an answer. The benchmark compares the answer to a known target.
That is clean. It is measurable. It is valuable.
But it leaves out the hardest parts of building enterprise AI systems.

In the real world, the answer is rarely sitting inside the prompt. The AI has to retrieve it. The data may live across a help center, PDFs, Zendesk tickets, SharePoint folders, product manuals, internal SOPs, customer records, API endpoints, or databases. The task may require a chain of actions, not a single response.
This is where many AI implementations break.
They do not break because the underlying model is useless. They break because the surrounding system is weak.
The agent needs memory. It needs context. It needs access control. It needs retrieval. It needs tool routing. It needs fallback behavior. It needs citation and verification. It needs observability. It needs to avoid making things up when the answer is missing.
That system around the model is often called the agent harness.
The harness is what turns a model from a conversational engine into a work-execution system.
What Is an Agent Harness?
An agent harness is the architecture around an AI model that helps it complete tasks.
It determines how the agent plans, searches, retrieves data, calls tools, uses APIs, reads files, verifies answers, and decides whether it is done.
A strong agent harness does not assume the model is always right. In fact, the best harnesses assume the opposite: the model may be wrong, incomplete, overconfident, or misled unless the system checks its work.
That is why high-performing agents usually need several layers around the base model:
- A planning layer to decompose tasks.
- A retrieval layer to find relevant knowledge.
- A tool layer to call external systems.
- A verification layer to check intermediate and final answers.
- A resilience layer to recover from failed tools, bad sources, and incomplete information.
- A finalization layer to return a clean, exact answer.
- An observability layer so humans can understand what happened.
This is also why simply choosing a better base model is not enough.
A stronger model helps. But without a strong harness, even a frontier model can wander, hallucinate, over-search, under-search, misuse tools, or stop too early.
For enterprise AI, the harness is often the difference between a great demo and a reliable production system.
Where RAG Fits In
Retrieval-Augmented Generation, or RAG, is one of the foundational pieces of reliable agent architecture.
RAG gives an AI system access to external knowledge instead of forcing it to rely only on the model’s training data. In an enterprise setting, that external knowledge is usually the company’s own content: documentation, manuals, policies, tickets, contracts, help articles, onboarding material, compliance files, product data, and internal knowledge bases.
CustomGPT.ai’s RAG API, for example, is designed to help developers deploy enterprise-grade RAG applications through RESTful endpoints, SDKs, and managed infrastructure. The platform also supports ingestion from sources such as websites, PDFs, Google Drive, SharePoint, Notion, Confluence, and more.
This is the first layer of agent reliability: grounding.
But RAG alone is not the full answer.
RAG helps the agent know where to look. The agent harness helps the agent decide what to do next.
A production-grade system needs both.
RAG provides the context. The harness provides the operating loop.
Together, they allow an agent to retrieve relevant evidence, reason over it, use tools when needed, verify its work, and produce a reliable answer.
The next generation of enterprise AI will not just be “ask a question, get an answer.” It will be:
- Research this issue.
- Compare these documents.
- Draft the response using approved policy.
- Check whether the customer is eligible.
- Find the latest contract clause.
- Summarize the relevant tickets.
- Escalate if confidence is low.
- Produce the final answer with citations.
- Take action in the right system.
And GAIA is one of the clearest public benchmarks for whether an AI system can perform that kind of multi-step work.
How GAIA Works
GAIA contains 466 questions, with a large portion of the answers held back for private leaderboard evaluation. The benchmark is split into public validation/dev sets and private test sets, so systems can be evaluated against held-out tasks rather than only public examples.
The process is straightforward:
- The agent receives a question.
- It may receive an attached file.
- It uses tools, search, browsing, code, file parsing, or other capabilities to solve the task.
- It submits a final answer.
- The benchmark compares the answer against the hidden ground truth.
- Scores are reported overall and by difficulty level.
The official leaderboard reports scores across Level 1, Level 2, and Level 3. Level 3 is the hardest tier and is meant to require a stronger jump in capability.
This structure rewards systems that can complete the entire loop.
Not just reasoning. Not just retrieval. Not just tool use. Not just answer formatting.
All of it.
That is why GAIA has become a useful lens for evaluating agents.
What CustomGPT.ai Achieved on GAIA
CustomGPT.ai Research Lab reached 93.36% overall on the GAIA benchmark. The official GAIA leaderboard lists CustomGPT.ai Research Lab v44 with an average score of 93.36%, including 97.85% on Level 1, 91.82% on Level 2, and 89.80% on Level 3, with a submission date of June 3, 2026.
CustomGPT.ai’s own research write-up reports that this represented 281 correct answers out of 301 private held-out tasks, including 44 out of 49 on Level 3. The same write-up states that this result came from an agent harness built around public frontier models, verification, resilience, and tool use, not from training a new foundation model.
That last point is the most important one.
This was not a “we trained a bigger model” result.
It was a systems result.
It showed that the architecture around the model can materially change what the agent is capable of doing.
What a #1 GAIA Result Really Means
A top GAIA score is strong evidence that an AI agent system can perform real-world, multi-step tasks better than most competing systems on that benchmark.
It means the system demonstrated strength in:
- Understanding ambiguous real-world tasks.
- Choosing and sequencing tools.
- Searching and retrieving information.
- Handling documents and files.
- Recovering from failures.
- Verifying answers.
- Returning precise outputs.
For CustomGPT.ai, the result is especially meaningful because it aligns with the company’s core product direction: reliable, grounded, enterprise-grade AI agents.
Enterprises are not looking for agents that merely sound smart. They need agents that can be trusted with workflows where accuracy, source grounding, access control, and reliability matter.
That is the deeper meaning of the GAIA result.
It is not just a leaderboard position. It is evidence that CustomGPT.ai has built strong agent-harness capabilities around the exact problems that make enterprise AI hard.
What It Does Not Mean
It is equally important to be precise about what a GAIA score does not prove.
A high GAIA score does not mean an AI system has achieved AGI. It does not mean the system is better than humans at every kind of work. It does not mean every enterprise deployment will automatically achieve the same success rate. It does not mean benchmarks replace customer-specific testing. It does not mean the base model alone deserves all the credit.
GAIA is a benchmark. A valuable benchmark, but still a benchmark.
It tests a particular distribution of tasks. Those tasks are broader and more realistic than many exam-style evaluations, but they are not a perfect replica of every enterprise environment.
Enterprise deployments introduce their own complexity:
- Private data.
- Permission boundaries.
- Compliance constraints.
- Messy internal documents.
- Outdated knowledge.
- Conflicting sources.
- Workflow-specific business rules.
- Human approval steps.
- Tool and API reliability issues.
- Security requirements.
So the right conclusion is not:
“GAIA proves the agent will solve everything.”
The right conclusion is:
GAIA provides strong external evidence that the agent architecture is capable of robust, multi-step, tool-using task completion.
That is the claim that matters.
And it is a defensible one.
Why This Matters for Enterprises
The enterprise AI conversation is shifting.
In 2024 and 2025, many teams were asking:
“Which model should we use?”
In 2026, that question is no longer enough.
Most companies can access strong models. They can call OpenAI, Anthropic, Google, Meta, Mistral, or other open source providers. The model layer is powerful, but increasingly available.
The harder question is now:
How do we make these models reliable inside our actual business workflows?
That is where the moat is moving.
The hard parts are not just prompting. They are:
- Data ingestion.
- Retrieval quality.
- Permission-aware access.
- Citation and source grounding.
- Tool orchestration.
- Verification.
- Observability.
- Security.
- Evaluation.
- Continuous improvement.
- Failure handling.
- Human-in-the-loop controls.
CustomGPT.ai has already focused heavily on grounding and anti-hallucination. The platform’s anti-hallucination approach is built around keeping responses within provided context, giving users control when the chatbot is uncertain, and providing source citations for transparency.
The GAIA result adds another layer to that story.
It shows that CustomGPT.ai’s research work is not only about retrieving answers from knowledge bases. It is also about making agents plan, act, verify, and recover.
That is the next frontier.
The Enterprise Agent Stack
A useful way to think about enterprise agents is as a stack.
At the bottom is the model.
Above that is retrieval.
Above retrieval is the agent harness.
Around everything are governance, security, observability, and user experience.

A simplified enterprise agent stack looks like this:
1. Foundation models
These provide language understanding, reasoning, generation, summarization, and multimodal capabilities.
2. Enterprise knowledge layer
This is where RAG matters. The agent needs access to the company’s trusted data, not just public web knowledge or model memory.
CustomGPT.ai supports business data ingestion from Google Drive, SharePoint, YouTube, websites, files, and more than 100 sources.
3. Tool and action layer
The agent needs to call tools: search, code execution, APIs, CRMs, help desks, ticketing systems, calendars, databases, calculators, and internal apps.
4. Planning layer
The agent needs to decide what steps are required and in what order.
5. Verification layer
The agent needs to check whether the answer is supported by evidence.
6. Resilience layer
The agent needs fallback paths when a source, API, parser, or tool fails.
7. Governance layer
The enterprise needs access control, auditability, privacy, compliance, and security. CustomGPT.ai’s security page states that the platform is SOC 2 Type II compliant and supports enterprise security and privacy standards.
8. User experience layer
The agent needs to fit into the place where work happens: support workflows, employee search, websites, internal portals, Slack, help desks, developer tools, or customer-facing products.
GAIA mainly tests the middle of this stack: planning, tool use, retrieval, verification, and resilience.
That is why it is strategically important.
It evaluates the part of the system that turns AI from a chat interface into an execution layer.
Why “Agentic RAG” Is the Real Opportunity
RAG was the first major step toward making LLMs useful in enterprises.
Instead of asking a model to answer from memory, RAG lets the system retrieve relevant information from trusted content.
That made AI more accurate. It made answers more current. It reduced hallucination risk. It made enterprise knowledge usable.
But the next step is agentic RAG.
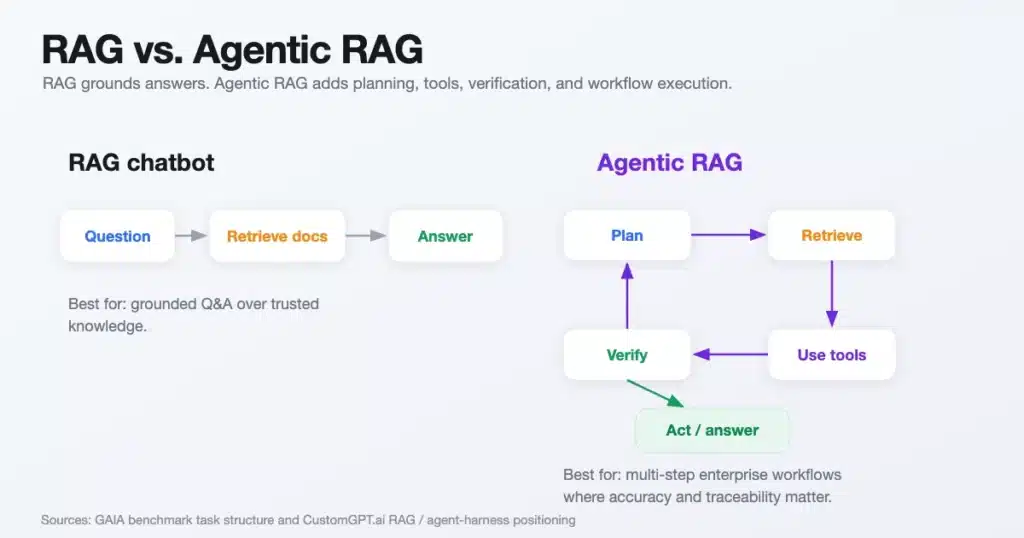
Agentic RAG means the system does not just retrieve and answer. It plans, searches, compares, verifies, acts, and escalates.
For example:
A normal RAG chatbot can answer:
“What is our refund policy?”
An agentic RAG system can handle:
“Review this customer’s last three tickets, check whether they qualify for a refund under the latest policy, draft a response with citations, and flag it for manager approval if confidence is below 90%.”
That requires more than retrieval.
It requires a workflow.
This is where GAIA becomes such a useful benchmark. GAIA-style tasks resemble the mechanics of real enterprise work:
- Find the right information.
- Use the right tool.
- Interpret the evidence.
- Avoid bad assumptions.
- Return the exact answer.
That is what businesses need from AI agents.
The Real Lesson: Models Answer, Systems Execute
The most important lesson from GAIA is that agent performance is a systems problem.
The base model matters, but the surrounding architecture often determines whether the agent succeeds. That architecture includes planning, retrieval, tool use, validation, uncertainty handling, recovery, stopping criteria, and auditable final answers.
For enterprises, this is the practical takeaway: strong agent performance does not require owning the biggest foundation model. It requires building a reliable execution system around the model.
What Buyers Should Learn From GAIA
For enterprise teams evaluating AI agents, GAIA offers a useful mental model.
Do not only ask:
“Which model powers this?”
Also ask:
- How does the agent retrieve trusted information?
- Can it cite its sources?
- Can it use tools?
- Can it handle files?
- Can it recover when a tool fails?
- Can it verify its answer?
- Can it avoid answering when evidence is missing?
- Can it operate inside our security and access-control requirements?
- Can we observe what it did?
- Can we evaluate it against our own workflows?
These are the questions that separate production AI from demos.
A beautiful demo can be built with almost any frontier model.
A reliable enterprise agent requires a full system.
What Builders Should Learn From GAIA
For AI builders, GAIA is also a reminder that agent engineering is different from chatbot engineering.
A chatbot loop is simple:
User asks. Model answers.
An agent loop is more complex:
User asks. Agent plans. Agent retrieves. Agent uses tools. Agent checks results. Agent revises the plan. Agent verifies. Agent finalizes. Agent records what happened.
Every step can fail.
The search result may be wrong. The file parser may miss a table. The model may misunderstand the question. The calculator may need structured inputs. The tool may timeout. The source may be outdated. The agent may stop too early.
That is why agent reliability requires engineering discipline.
The winning systems will not be the ones with the longest prompts. They will be the ones with the strongest architecture.
What Comes Next
AI agents are moving from experimental demos into production systems.
As agents take on customer support, research, compliance, onboarding, sales enablement, operations, and internal knowledge work, businesses will need clearer ways to evaluate whether these systems can actually complete tasks.
GAIA is not the final benchmark for agents. No single benchmark can be. But it is one of the clearest early signals of what matters: execution, verification, resilience, and trustworthy automation.
That is the future of enterprise AI.
Conclusion: Why the GAIA Result Matters
CustomGPT.ai’s #1 GAIA result matters because it points to where enterprise AI is going.
The first phase was model access. The second phase was RAG. The third phase is agentic execution: AI systems that can reason over trusted data, use tools, verify evidence, recover from failure, and complete real workflows.
That is what GAIA measures, and that is what CustomGPT.ai is building toward.
Want to see how CustomGPT.ai applies this agent-harness approach in practice?
Read the GAIA Research Lab write-up to see how CustomGPT.ai reached 93.36% on the benchmark using retrieval, tool use, verification, and resilience.
FAQ
What is GAIA?
GAIA is a benchmark for General AI Assistants. It evaluates whether AI systems can complete real-world tasks requiring reasoning, web browsing, multimodal understanding, tool use, and precise answer generation.
Why is GAIA important?
GAIA is important because it tests agent execution, not just model intelligence. Many AI systems can answer isolated questions, but GAIA tests whether they can plan, retrieve information, use tools, inspect files, verify evidence, and return exact answers.
How many questions are in GAIA?
The GAIA paper describes 466 questions, with answers to 300 held back to power the leaderboard. The official leaderboard describes the benchmark as containing more than 450 non-trivial questions with unambiguous answers.
What does GAIA Level 3 mean?
Level 3 is the hardest GAIA tier. According to the official leaderboard description, Level 3 is intended to indicate a strong jump in model and agent capability.
What score did CustomGPT.ai achieve?
The official GAIA leaderboard lists CustomGPT.ai Research Lab v44 with a 93.36% average score, including 97.85% on Level 1, 91.82% on Level 2, and 89.80% on Level 3.
Did CustomGPT.ai train a new foundation model for this?
No. CustomGPT.ai’s research write-up states that the result came from an agent harness built around public frontier models, verification, resilience, and tool use, not from training a new model.
Does a high GAIA score mean AGI?
No. A high GAIA score does not prove AGI. It shows strong performance on a specific benchmark for general AI assistants and tool-using agents.
Why does this matter for enterprise AI?
Enterprise AI needs reliable execution over trusted data. GAIA tests many of the same capabilities needed in production: retrieval, tool use, file understanding, verification, precision, and recovery from failure.
How is this related to RAG?
RAG gives agents access to trusted external knowledge. Agentic systems add planning, tool use, verification, and workflow execution around that knowledge. Together, they form the foundation for reliable enterprise AI agents.

Founder @ CustomGPT.ai , Husband & Father of 4, Avid cricket wicket-keeper